网站公告:


400-123-4567
THE LATEST INFORMATION
| 九天资讯 |
开始之前,请问你是不是考虑执行贝叶斯超参数优化,但又不确定如何操作?听说过各种超参数优化库,如前两次介绍的模型调参神器:Hyperopt?| 使用 Hyperopt 和 Plotly 可视化超参数优化,但又想知道 Scikit Optimize 是否适合?这时,你应当认真阅读完本文,并且点个赞加个收藏~
几乎所有实际情况,都需要搜索在交叉验证中能够让机器学习模型达到最佳性能的参数,这类参数可以使得模型达到最佳但泛化性。scikit-learn 中的一个标准方法是使用类,它为每个参数尝试一组值,并简单地枚举参数值的所有组合。随着新参数的增加,这种搜索的复杂性呈指数增长。一种更具可扩展性的方法是使用,但是它没有利用搜索空间的结构。
Scikit-optimize 算是的一个替代品,它利用贝叶斯优化,其中一个称为“surrogate”的预测模型用于对搜索空间进行建模,并用于尽快获得良好的参数值组合。
SKOPT 通过创建另一个模型来简化超参数优化,该模型通过更改其超参数试图最小化初始模型损失。
Scikit Optimize 的 API 真的特别好用。首先定义搜索空间:
搜索空间定义了我们想要在搜索中探索的超参数以及探索边界。大多数参数是整数、实数(浮点数)或分类。可以使用 skopt.space 类为每个参数定义搜索空间。即可以从三个选项中进行选择:
- 用于浮点数参数,从(a,b)范围通过均匀对数均匀采样
- 用于整数参数,从(a,b)范围内均匀采样,
- 用于分类(文本)参数,将从选项列表中抽取一个值。例如,如果正在训练 lightGBM,则可以通过 ['gbdt','dart','goss'] 选择参数值。
它不支持嵌套搜索空间,这就解释了某些超参数组合完全无效,但有时候真的很方便的情况。
HPO_PARAMS 定义了用来寻找最佳参数的过程的一些基本属性。
定义了要进行多少次参数迭代。
定义了模型将进行的随机迭代次数,以便在开始寻找最佳位置之前对搜索空间进行更广泛的探索。在这种情况下,让模型在开始寻找最佳区域之前随机探索搜索空间进行 20 次迭代。
选择用于优化初始模型的超参数的模型,“ET”代表额外的应力回归器。
定义了最小化的函数,“EI”指我们希望使用损失度量的减少作为改进目标。
定义最小化的目标函数。
模型使用目标函数来衡量每次迭代,在提高基础模型性能方面的效果。它将每次迭代中选择的超参数组合作为输入,并输出基本模型性能(隐藏在评估器类中)。
使用包装器来转换目标函数,以便它接受列表参数(默认由优化器传递),同时保留特征名称。
设置评估器类的评估参数函数。创建了一个类来将与模型训练和评估相关的所有代码与模型隔离开来,以提高可读性。
使用训练和验证数据实例化评估器类,选择我们想要评估的模型,然后搜索最佳参数集以最小化验证集上的 RMSE。另外,在每次迭代后添加了一个打印语句,这样更容易跟踪进度。
现在我们已经准备好使用最后一行代码开始搜索最佳超参数了:
这里使用了函数,它使用了我们已经准备好的 3 个参数——objective、SPACE 和 HPO_PARAMS。
对于在中定义的迭代次数,它在中选择一组参数,将它们提供给函数,目标函数使用函数来检查这些参数在我们的模型中的执行情况。当我在函数中添加打印语句时,我们可以跟踪每次迭代之间的进度。
有四种优化算法可供选择:
你可以对参数进行简单的随机搜索。这里没有什么特别之处,但是如果需要的话,在相同的API中使用这个选项进行比较是很有用的。
这两种方法以及下一节中的方法都是贝叶斯超参数优化(也称为基于顺序模型的优化SMBO)的例子。这种方法背后的思想是用随机森林、极度随机树或梯度增强树回归估计用户定义的目标函数。
在对目标函数的每一次超参数运行后,算法根据经验猜测哪一组超参数最有可能提高分数,应该在下一次运行中尝试。它是通过对许多点(超参数集)进行回归或预测,并根据所谓的获取函数选择最佳猜测点来完成的。
:负期望改进和负概率改进。如果你选择其中一个,你也应该调整参数。基本上,当你的算法在寻找下一组超参数时,你可以决定你愿意在实际目标函数上尝试多大程度的预期改进。值越高,回归函数期望的改进(或改进的可能性)就越大。
:置信度下限。在这种情况下,你需要仔细选择下一个点,限制下跌风险。可以决定在每次运行时要承担多大的风险。通过设置kappa参数越小,倾向于采用所有参数;通过设置kappa参数越大,倾向于采用搜索空间。
还有选项,它们同时考虑了目标函数和执行时间产生的分数,但本文还没有尝试使用他们,感兴趣的读者可以尝试~
该优化算法是近似的高斯过程而不是使用树回归。
从用户的角度来看,这种方法的附加价值在于,无需事先决定一个采集函数,而是可以让算法在每次迭代时选择EI、PI和LCB中的最佳函数。只需将采集函数设置为并进行试验。
需要考虑的另一件事是在每次迭代中使用的优化方法,即或。对于这两种方法,采集函数都是在搜索空间中随机选择的点数(n_points)上计算的。如果选择,则选择值最小的点。如果选择,算法将从最佳随机尝试点() 中选取若干个点,并从每个点开始运行优化。所以基本上,如果你不关心执行时间,方法只是比方法的一个改进。
使用官网strategy-comparison来比较以上几个优化方法。
使用benchmarks.branin函数作为昂贵函数的模型,此示例的目标是在尽可能少的迭代中找到这些最小值之一。一次迭代被定义为对benchmarks.branin函数的一次调用。
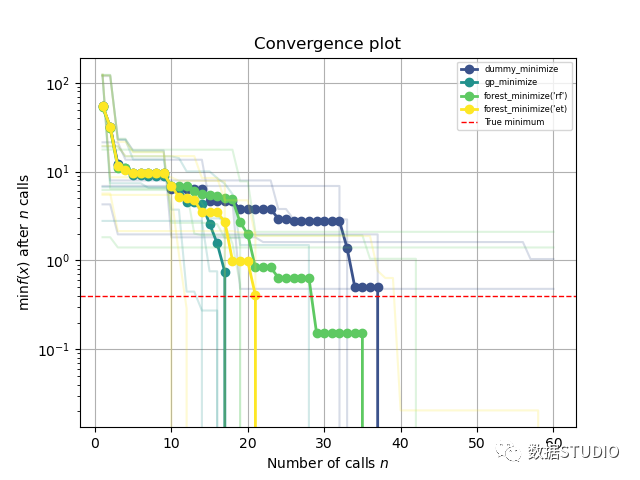
该图显示了找到的最小值(y 轴)作为迄今为止执行的迭代次数(x 轴)的函数。红色虚线表示benchmarks.branin函数最小值的真实值。
在前十次迭代中,所有方法的表现都一样好,因为它们都是在第一次拟合各自的模型之前创建十个随机样本开始的。在第 10 次迭代之后,下一个评估点benchmarks.branin由优化模型引导,也就是差异开始出现的地方。
我非常喜欢有一个简单的选项来传递回调。例如,我可以通过简单地添加3行代码来监控训练。
可以选择在每次迭代中提前停止或保存结果。
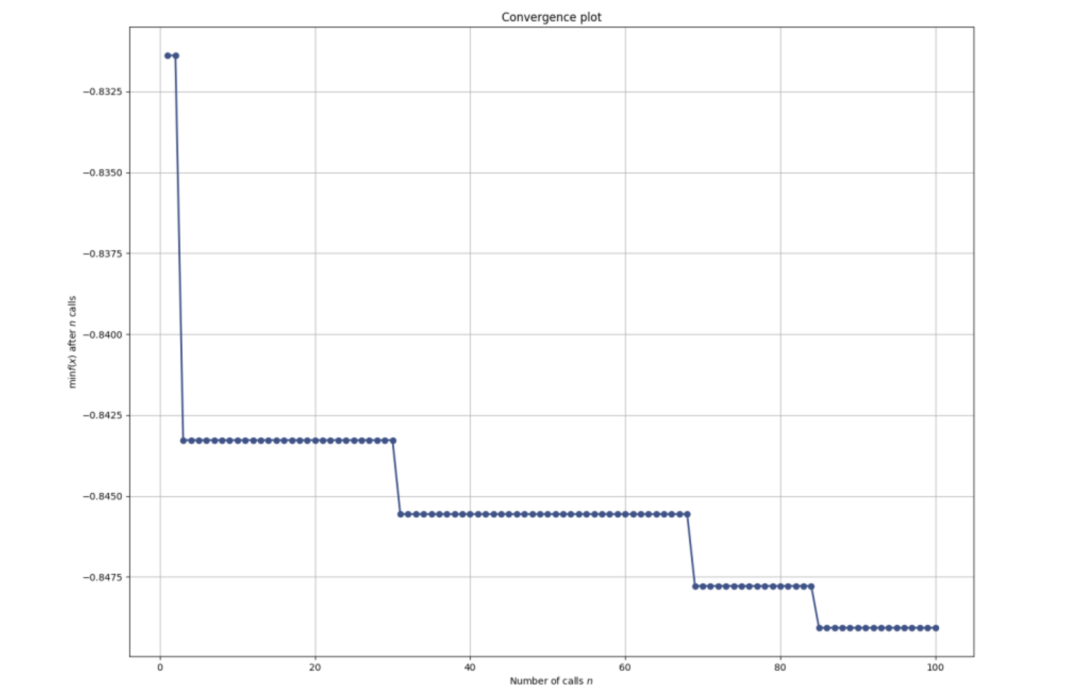
可以从评估收敛结果开始,看看我们的模型在每次迭代中的最佳性能如何提高。
可以使用 SKOPT 来可视化我超参数搜索,skopt中有三个绘图实用程序。不得不说可视化选项真的非常棒!
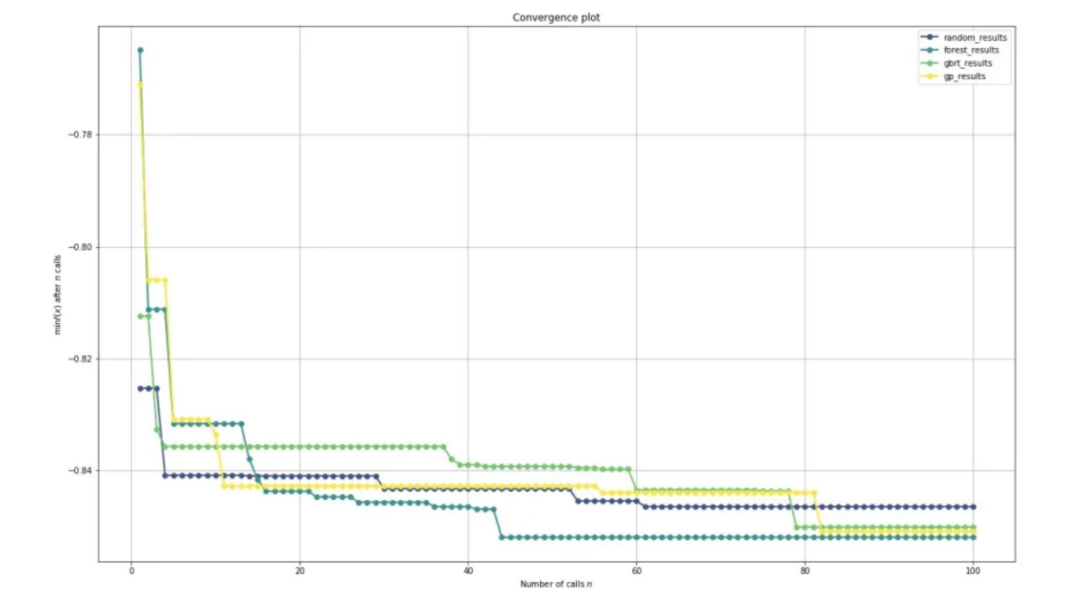
它通过在每次迭代中显示最好的结果来可视化优化的进展。
它最酷的地方在于,可以通过简单地传递结果对象列表或(name, results)元组列表来比较许多策略的进展。
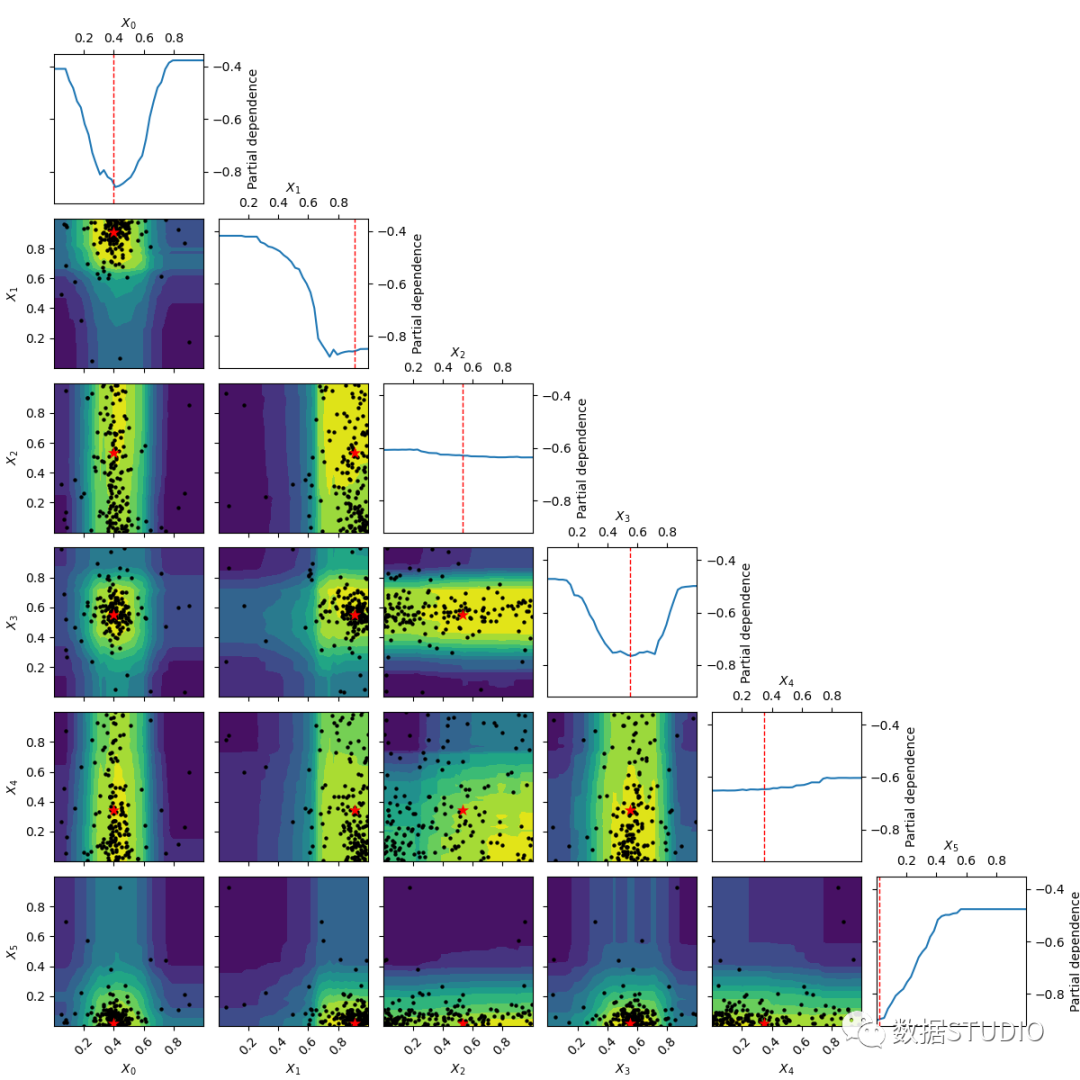
这个绘图可以让你看到搜索的发展过程。对于每个超参数,可以看到搜索值的直方图。对于每一对超参数,采样值的散点图用颜色表示,从蓝色到黄色。
例如,对于forest_minimize策略,可以清楚地看到它收敛于它更多地搜索的空间的某些部分。而随机搜索策略并不能看到这样的演变。
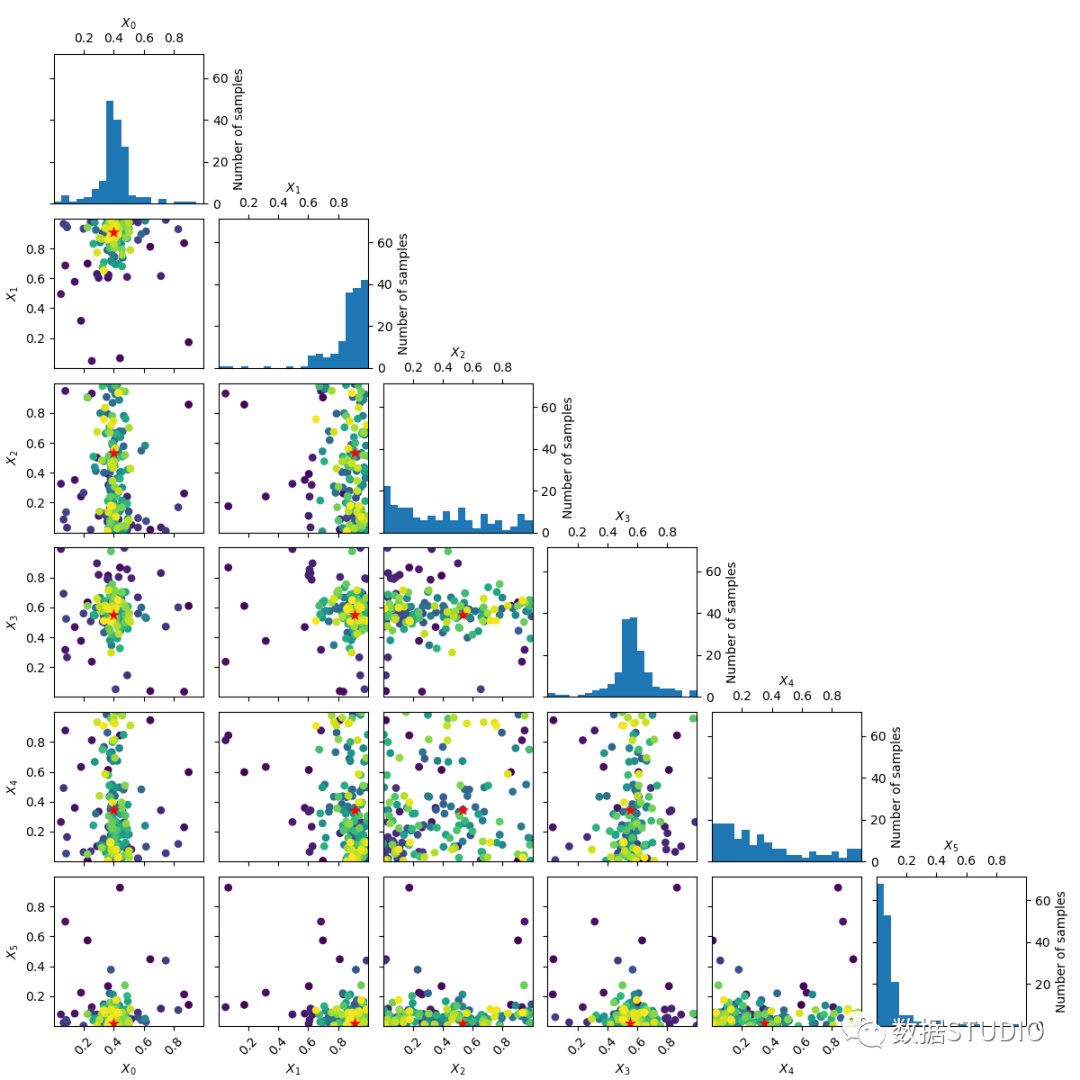
你可以直观地了解与超参数相关的分数敏感性。可以决定空间的哪些部分可能需要更细粒度的搜索,哪些超参数几乎不影响分数,并且可能从搜索中删除。
我们可以通过调用来获得最好的参数,但输出结果列表中没有 param_name ,所以这里我创建了一个辅助函数来将其转换为更易于阅读的字典。
每个优化函数都带有参数,该参数被传递给。这样的话,即使优化运行是按顺序进行的,我们也可以通过利用更多资源来加速每次运行。
有和函数用于保存和加载结果对象。
可以通过和参数从保存的结果中重新启动训练。例如:
总之,一方面有很多选项可以调优超参数,可以使用回调来控制训练。另一方面,你只能在平面空间中搜索,需要自己处理那些不可用的参数组合。
它包含大量示例,所有函数和方法的文档字符串,并且只需要花了几分钟的时间就可以入门。完全可以自己去scikit-optimize官方文档网页看看。
SKOPT 是一个很棒的的超参数优化工具,它结合了易用性和出色的可视化来分析结果。
该库也非常通用,因为我们可以随意设置目标函数,我们可以使用它来评估任何模型和任何超参数集。
最后,希望你看了近期的超参数优化系列文章,尽量不必在这些繁琐的网格搜索上浪费时间。这里可以尝试 SKOPT,这样你就可以在很短的时间内,利用另一个模型为你的目标模型找到最佳超参数。点个赞哇!
参考资料
[1]
scikit-optimize官方文档网: https://scikit-optimize.github.io/stable/
-------- End --------




