网站公告:


400-123-4567
THE LATEST INFORMATION
| 九天资讯 |
我们都知道几乎所有的神经网络采取的是梯度下降法来对模型进行最优化,其中标准的权重更新公式:
大致可以分为两类:
import torch
import matplotlib.pyplot as plt
%matplotlib inline
from torch.optim import *
import torch.nn as nn
class net(nn.Module):
def __init__(self):
super(net,self).__init__()
self.fc = nn.Linear(1,10)
def forward(self,x):
return self.fc(x)
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
lr_list = []
for epoch in range(100):
if epoch % 5 == 0:
for p in optimizer.param_groups:
p['lr'] *= 0.9
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
更新策略:将每个参数组的学习率设置为初始lr乘以给定函数。当last_epoch=-1时,将初始lr设置为lr
参数
注意:
在将optimizer传给scheduler后,在shcduler类的__init__方法中会给optimizer.param_groups列表中的那个元素(字典)增加一个key="initial_lr"的元素表示初始学习率,等于optimizer.defaults['lr']。
使用示例
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1))
# train
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
# -----------------使用示例2------------------
import numpy as np
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
lambda1 = lambda epoch:np.sin(epoch) / epoch
scheduler = lr_scheduler.LambdaLR(optimizer,lr_lambda = lambda1)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')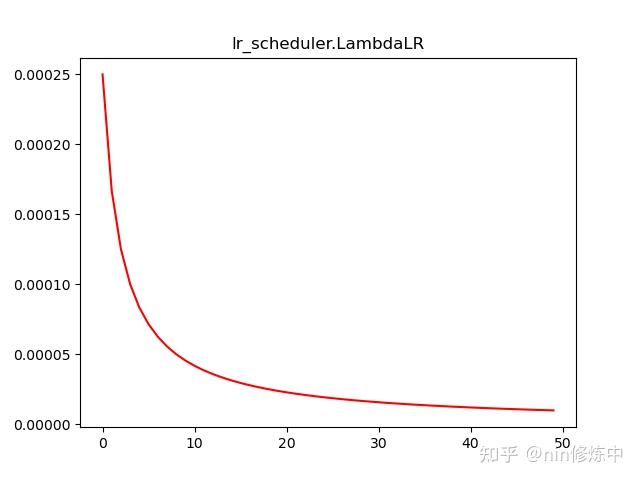
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
更新策略:每经过step_size 个epoch,做一次学习率decay,以gamma值为缩小倍数。
注意:此函数产生的decay效果,可能与函数外部的对于学习率的更改同时发生,当last_epoch=-1时,将初始lr设置为Ir。
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')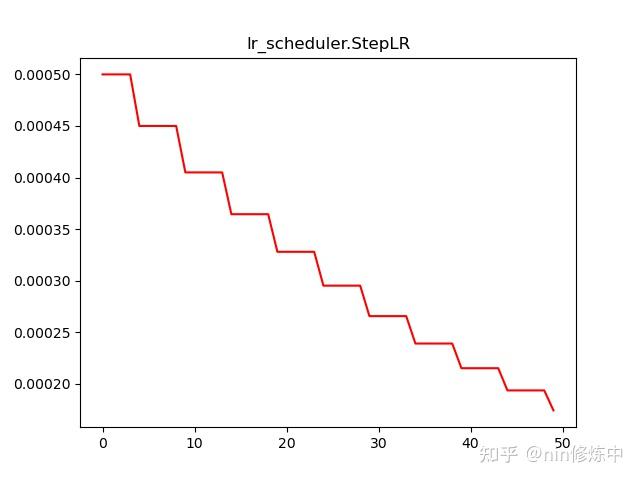
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
**更新策略:**一旦达到某一阶段(milestones)时,就可以通过gamma系数降低每个参数组的学习率。
注意:此函数产生的decay效果,可能与函数外部的对于学习率的更改同时发生,当last_epoch=-1时,将初始lr设置为Ir
可以按照milestones列表中给定的学习率,进行分阶段式调整学习率
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.MultiStepLR(optimizer,milestones=[20,80],gamma = 0.9)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')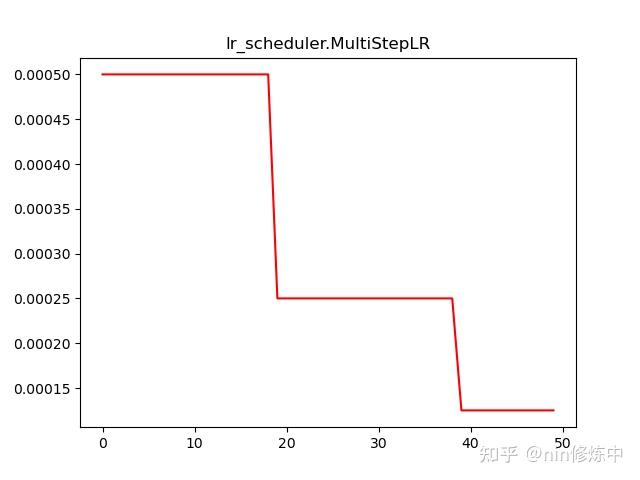
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
更新策略:每一次epoch,lr都乘gamma
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')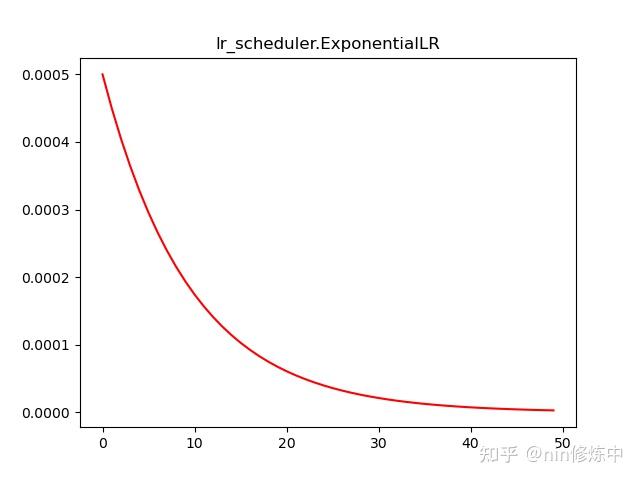
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
更新策略:按照余弦波形的衰减周期来更新学习率,前半个周期从最大值降到最小值,后半个周期从最小值升到最大值
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20)
for epoch in range(50):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')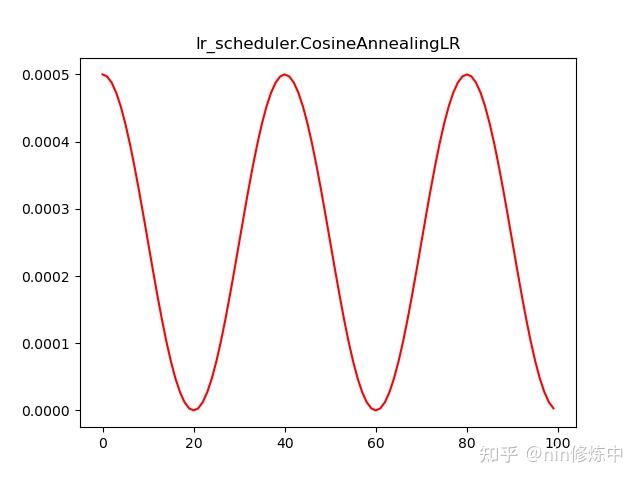
参考链接:


