网站公告:


400-123-4567
THE LATEST INFORMATION
| 九天资讯 |
Adam作为一种自适应的优化算法, 结合了Momentum以及RMSprop算法, 一方面参考动量作为参数更新方向, 一方面计算梯度的指数加权平方. Adam在深度学习领域有广泛的实用性, 同时也是过去五年来被cite数量最多的scientific paper, 根据Nature Index and Google Scholar, 被戏称为AI Paper计数器.
基于和
这两个移动平均的衰减率, 我们可以得到一阶矩
, 二阶矩
, 可以分别看作梯度的平均值和方差.
通常我们会需要对以及
进行偏差修正(bias correction):
从而计算参数更新差值为:
其中是学习率, 也就是我们常说的learning rate. 但是在实际implement中, 在代码实现层面通常会将bias correction加入到
的计算中, 即:
实际上得到的参数更新差值为:
上述步骤也在Adam原文中的算法流程中得到体现:

那么为什么我们要进行偏差修正呢, Bias Correction在训练过程中扮演了什么样的作用呢, 我们先来看一下论文原文的解释:
In case of sparse gradients, for a reliable estimate of the second moment one needs to average over many gradients by chosing a small value of β2; however it is exactly this case of small β2 where a lack of initialisation bias correction would lead to initial steps that are much larger.
以公式来具体论证的话, 在时间步, 我们以指数移动平均来举例, 假设
有初始化
, 根据
, 我们可以得到
在任意时间步的累加状态:
我们想要知道的是Adam中模拟的指数移动平均的期望
能否对应真实二阶矩
, 这里有没有存在一定偏差呢, 我们不妨来计算一下
:
计算一个简单的等比数列求和完成推导后, 我们可以看到偏移系数已经出现在我们面前了, 对于一阶矩
同样可以推导出偏移系数
, 这是由零值初始化导致的, 所以我们需要计算参数更新差值时进行修正.
举例来说, 在实际训练中通常我们会采用,
作为超参数, 并将
初始化
. 将
带入上述公式中, 我们不妨来看一下训练初期会发生什么:
看到矩估计值(moment estimates)实际上会很大, 很容易往初始值0的方向偏移, 特别是在模型训练初期或者很小的时候(这往往也就是我们通常训练会出现的场景).
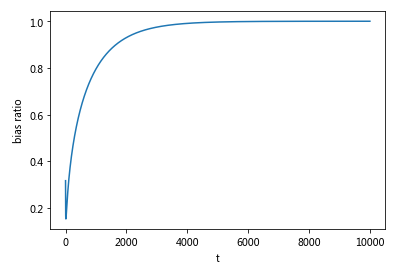
下图为bias correction的比例在前10000个steps下的曲率图, 调整比例先减小再变大最后趋近于1.
权重衰减是一种比较常用的正则化方法, 会在参数更新时, 引入一个衰减系数.
其中在标准SGD优化算法下, L2 regularization 和 Weight decay时等价的. L2 regularization在参数更新时加上一个L2惩罚项:
上述公式中的为惩罚系数, 可以看到当
时, L2 regularization等价于Weight decay.
也正是因为二者在标准SGD优化算法下的等价性, 二者也经常同日而语, 在很多深度学习库中也会以Weight decay的形式来实现L2 regularization, 即不直接改变loss function以及训练目标函数, 直接在梯度更新值上加上. 这样的做法固然方便合理没有增加额外的计算开支, 但是[ICLR 2019]Decoupled Weight Decay Regularization指出二者在引入动量概念或者Adam这样的自适应梯度下降算法下其实并不是等价的.
考虑最简单的Momentum的方法来证明这种不等价性, ,
为动量因子:
为需要优化的函数加入L2 regularization
, 得到正则化后的动量
以及在时间步下的参数更新值
对于Weight decay, 我们直接在权重更新进行衰减:
而一般情况下不存在超参数 对于所有时间步下的
满足
, 从而证伪一致性. 而Adam这种更加复杂的梯度下降算法只会让这种差异性更大.
经过一番整理与讨论, 我们来归纳一下Adam optimizer中二者的差异:
尽管上述两种正则化机制都以相同的速率迫使权重接近于零. 但是后者会导致惩罚系数与学习率
之间存在耦合, 为了解耦这两个超参数的影响, 进而孵化出了**Adam with decoupled weight decay (AdamW)**算法.

用公式的形式来翻译一下上述伪代码, 理解一下最后呈现出来的
L2 regularization中, 我们通过时直接改变梯度值, 损失函数的梯度(
)和L2惩罚项的梯度(
)都被调整了, 然而调整系数与
相关而非
本身. 对应的
会有更大的值, 从而导致在梯度变大比较快速的方向上,
偏小, 从而降低了正则化的有效性.
乾坤大挪移搬运一下原论文的解读:
with L2 regularization, the sums of the gradient of the loss function and the gradient of the regularizer (i.e., the L2 norm of the weights) are adapted, whereas with decoupled weight decay, only the gradients of the loss function are adapted (with the weight decay step separated from the adaptive gradient mechanism). With L2 regularization both types of gradients are normalized by their typical (summed) magnitudes, and therefore weights x with large typical gradient magnitude s are regularized by a smaller relative amount than other weights. In contrast, decoupled weight decay regularizes all weights with the same rate λ, effectively regularizing weights x with large s more than standard L2 regularization
最后我们从代码层面来回顾一下adam梯度下降算法的各种变体:
rescaled_grad=clip(grad * rescale_grad, clip_gradient) + wd * weight
m=beta1 * m + (1 - beta1) * rescaled_grad
v=beta2 * v + (1 - beta2) * (rescaled_grad**2)
lr=learning_rate * sqrt(1 - beta2**t) / (1 - beta1**t)
w=w - lr * m / (sqrt(v) + epsilon)grad=clip(grad * rescale_grad, clip_gradient)
m=beta1 * m + (1 - beta1) * grad
v=beta2 * v + (1 - beta2) * (grad**2)
lr=learning_rate * sqrt(1 - beta2**t) / (1 - beta1**t)
w=w - lr * (m / (sqrt(v) + epsilon) + wd * w)grad=clip(grad * rescale_grad, clip_gradient)
m=beta1 * m + (1 - beta1) * grad
v=beta2 * v + (1 - beta2) * (grad**2)
lr=learning_rate
w=w - lr * (m / (sqrt(v) + epsilon) + wd * w)BERT等相关预训练模型的tensorflow官方实现当中应用的就是不带bias correction的AdamW算法
参考资料:


